

 首 页
首 页冯火:HIT数据库表设计实践
开始今天文章之前,请允许我先回顾前段时间在CHIMA公众号写了一篇文章“冯火:如何设计可以运行20年的新一代HIS系统”,我看到有一条留言说我的文章观点独到,你可能会好奇是我是怎么想到的?“携号转网”是我在别人文章里看到的,本质是解决“用户被运营商绑架”的问题,当时只是觉得这个了不起,没有想到它跟我从事的HIT有什么关系。那天听HIT专家网组织了“新一代医院信息系统”网课,提到“如何打造20年不做颠覆性改变”,其中又提到厂商需要开放,我突然想到HIT最大问题是“绑架”,本质上“携号转网”解决一样的问题,两件事情在我脑子里瞬间完成了碰撞,怎么可以做到“携号转网”,带着这个疑问,继续深思,运营商绑架的是什么,是手机号码,HIT厂商绑架的是什么,是“医疗数据”,再逐步展开分析,就有了你们看到的文章!
言归正传,既然上文中提到了如何设计“数据库”是关键。数据库设计特指关系型数据库设计,nosql不是本文所要讨论的内容。我们经常遇到HIT表结构设计的乱糟糟(也有少数公司设计精良的),可以用一个词来形容“随心所欲”,有命名像天书的、没有注释字段都是靠猜、不加相应索引导致系统跑段时间突然变“龟速”、有照搬教科书设计范式等等,数据库设计好与坏,你我心里都有一杆“秤”。
在今天大数据、人工智能非常火爆的情况下,对数据的质量非常重视,即当下有一个火热的词汇“数据治理”,我写了一篇文章“浅谈数据治理”(https://www.jianshu.com/p/ee4850a9a1be),大家有兴趣可以去看看。既然数据的源头基本来自“数据库”。怎么样设计出一个合理的数据库?这是一个很重要的问题,以下是根据我多年经验试着回答这个问题。

不合理的数据库设计
天书般的命名。你应该见过这样的命名(AKA01、AKA02、BAA、P1、P2等),软件开发有句俗话“代码即文档”,什么意思,看你的代码就像看你写的文档一样的易懂。这样的命名无疑增加大家的使用成本,有人说这样做是为了数据库安全,数据库的安全不是靠用不规范的命名就可以解决?再强调一次,安全问题本质非法访问未授权的资源!这是人为造成不便利,公司开发效率低、运维效率低。
表结构与注释分离。字段命名采用拼音缩写的,字段的注释没有在一起描述,很多软件公司不在数据库表直接写注释,而是单独用一个txt或者doc来记录,我个人认为这是一个不好的习惯,我们经常有这样的困惑,写sql的时候,突然想知道这个表这个字段是什么意思,第一种方法,靠猜,看它的记录是什么数据;第二种方法,打开公司提供的数据字典,ctrl+f查找这个字段是什么意思。或许你说这是为了技术保密,保密不是靠不写注释就可以保障的!这是人为造成不便利,用户、公司的开发、运维、实施也不方便,不经意间降低工作效率!
范式使用场景不对。首先了解范式的是什么,范式是用来解决数据冗余存储的问题的,范式别级越高,冗余度越小。由于经验缺乏的关系,业务数据表经常被设计成3NF,导致数据完整性受影响、增加写sql复杂程度问题。为什么会有范式使用场景不对的,会有什么影响,后面我将举例说明。
基础表与业务表设计没有充分解耦。“解耦”这个词,大家并不陌生,在数据库这个层面,个人认为“基础表与业务表”需要充分解耦。这个怎么理解,表之间关系通常是一对一、一对多、多对多,问题主要出在“一对多”这种关系,我们一般在维护了“外键”来表达这种关系。举例说明,“医嘱表”设计一个来自于“医生表”外键,设计人员本意要表达一种“一对多”关联关系。在实际使用过程当中会产生什么问题,第一个问题,业务表数据量通常是非常大,势必增加系统开销;第二个问题,假设删除某个医生,数据库就会关联业务表的外键报错,业务表一般认为不可变的数据(人为后台修改除外),影响用户体验。有经验设计者,一般去掉这个外键,然后在注释当中写明“外键关系”,降低基础表与业务表耦合。
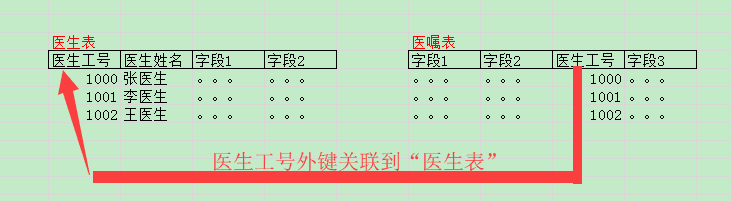
我总结的经验:1、业务数据表,一般设计冗余存储,可以不加外键,在注释当中说明这种“一对多”关系;2、基础数据表,一般设计成3NF,基础数据表之间可以加“外键”,遵循最小代价修改原则,后面我还会提到这个问题,因为十分重要。
关键字段没有索引。这个很好理解,系统跑了一段时间以后,由于没有对关键字段维护索引,系统突然变“龟速”。
我认为合理的设计
合理的命名。表、字段的命名,可以采用简写拼音、英语单词、英语单词缩写。比方说“患者姓名”字段,可以是xm(简写拼音)、patient_name(英语单词)、pat_name(英语单词缩写)。对于英文水平很高优先采用英语单词、英语单词缩写,对于英文差的,可以简写拼音,总之不要用“六亲不认”的命名。
表结构与注释一起

mysql表,外键描述
对于“业务数据”表结构设计,尽可能接近1NF
对于一些不经常变动基础的数据进行冗余保存到业务表,比如,保存“发票类别代码+发票类别名称”、“医生工号+医生姓名”、“科室代码+科室名称”、“结算方式+结算方式名称”等。这样做的目的,1、尽可能避免多表查询,考虑效率,因为业务数据是要被经常访问的,能访问一张表搞定,就不要访问两张表;2、保持历史数据独立完整性,比如,某位员工离职了,就把操作权限连同基础数据一起删除了,依然不影响历史数据查询。我们医院就有“结算方式”被禁用,导致有些系统无法读不出来历史数据了,原因是原来在开发软件时候,由于没有冗余存储,直接关联了基础表,导致读不出来。
对于“基础字典数据”表结构设计,尽可能接近3NF(尽量最小的修改代价原则)
范式级别越高,信息冗余就越小,但一般到3NF就可以,尽可能符合“尽量最小的修改代价原则”。基础数据由于记录少,多表查询一般不会有执行效率问题,数据冗余越小我们维护越方便,出错概率就越小,系统稳定性高。
基础表与业务表设计之间耦合问题,上文已经提及解决方案,在此不再赘述。关键字段没有索引问题,有时候需要专业的DBA来维护,在此不再赘述。
回顾理论知识
为了考虑广大读者的实际情况,更好理解文中所描述的内容,我还是把重要的理论知识跟大家简单回顾一下。
第一范式(1NF)指字段是否为复合字段,不可拆分,这个要看业务情况,比如姓名字段,你要不要拆分成“姓”、“名”2个字段。“地址”要不要拆分省市、县、街道。
第二范式(2NF)在1NF基础上,非主属性字段之间消除部分或完全依赖(另一种说法非主属性完成依赖于主键)。举例说明,非主属性数量、单价、金额之间存在依赖关系。

部分依赖
第三范式(3NF)在2NF基础上,非主属性字段之间消除传递依赖。举例说明,出生日期、年龄、是否成人,存在传递依赖。

传递依赖
"一对多"关系,一般在“多”的一方,维护一个“外键”表达这种关系。

一对多
"多对多"关系,使用中间表表达这种关系。
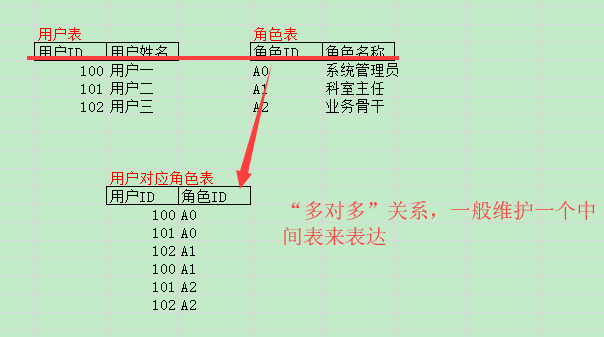
多对多
患者主索引设计实战(含视频)
(作者:广东省罗定市人民医院信息科 冯火)


CHIMA大讲堂第一期回放:
https://live.chima.org.cn/watch/975050
CHIMA大讲堂第二期回放:
https://live.chima.org.cn/watch/997828
CHIMA大讲堂第三期回放:
https://live.chima.org.cn/watch/1093145

