

 首 页
首 页中山大学附属第一医院:智能语音技术赋能超声科临床科研智慧一体化建设
2021年医院新兴技术创新应用典型案例征集活动共选出21篇典型案例,将于CHIMA2021大会上进行颁奖。
长期以来,中山大学附属第一医院(以下简称“中山一院”)超声科存在以下痛点:
(1)超声检查与放射影像不同,技术与诊断是同步进行,检查时间相对长,例如常规检查消化系统要求空腹,时间相对集中,病人都在等待区集中,时有患者等待的抱怨声,既不利于检查医生思考,更不利于病人对医院就诊服务的印象,直接影响了患者满意度。
(2)中山一院超声科多采用一台超声诊断设备配一名录入员人工键盘输入超声检查报告的方法,手动浏览采集的超声图像和调取历史管理病人检查结果,录入员人力成本投入巨大。
(3)诊间中超声设备与工作电脑为分开放置,医生需要频繁切换工作位置,一方面工作不变,另一方面也会打断诊疗活动的持续性。
(4)超声报告结构化录入过于复杂,耗时耗力,但对于科研非常重要,期待能够通过新技术实现更为便捷、准确的结构化录入。
中山一院超声科一直在寻求一种利用语音代替打字员的系统,采用虚拟助手辅助超声检查报告录入,结合超声诊断学知识、语音识别技术、自然语言理解知识库等多学科跨领域实现超声检查报告的语音录入,可减少或无需配备录入员。通过超声检查医师口述超声检查的超声描述及超声结论等信息,自动生成超声报告,或者配合超声报告模板,自动填充相应数值,提高了超声检查报告的录入效率和质量。
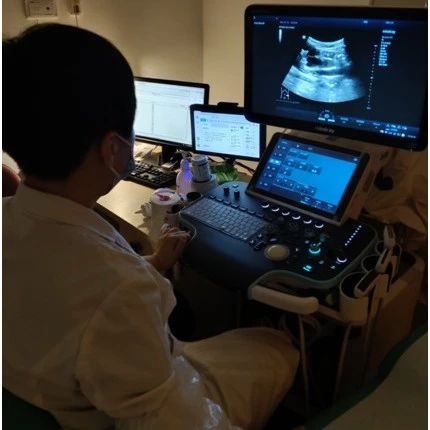
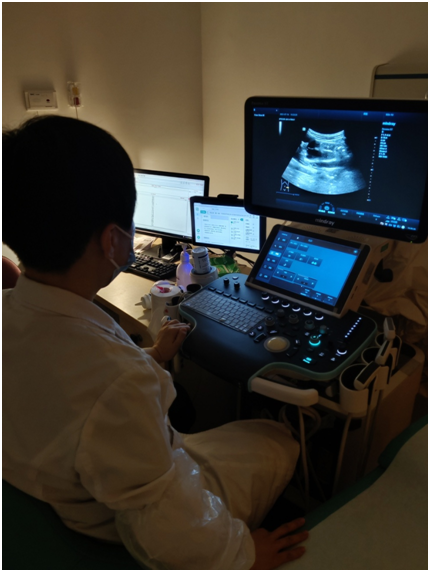
经过近一年的技术攻关,成功将智能语音技术应用于中山一院超声科超声检查场景中,实现单人全过程语音操控,完成超声报告的智能化语音录入,优化患者的就医流程,提高超声科医生的工作效率,获得超声科医生的高度评价,效果如图1所示。

结合国家制定的超声检查标准及中山一院特色的超声检查内容,我们对超声模板内容进行了详细的收集。为了让模板更贴合实际使用的场景,中山一院深度定制的超声语音报告模板、交互逻辑以及相应口述说法的确认。
(1)全过程语音交互:按照超声科检查流程,让医生通过语音方式完成超声报告的数值填槽,枚举选择、采集图像、保存打印等全过程语音交互操作。
(2)数值自动计算:在心脏超声中,有许多数值需要公式计算,在口述计算因子数值后,其他结果可按公式自动计算。如口述心脏超声中的E值和A值,可自动计算出E/A的比值。
(3)检查结论自动关联:将检查所见内容与检查结论自动关联,如检查所见中描述:肝脏弹性>7,检查结论中自动显示为:肝脏弹性测值增高。
(4)报告质检:如果报告中出现数值超出正常数值、部位上下描述矛盾、不同性别下产生不合理诊断的情况时,自动标注出不合理的地方,并告知医生标准设定值。
(1)声学前端技术
1)端点检测
端点检测是对输入的音频流进行分析,确定用户说话的有效语音的过程。一旦检测到语音流中的静音段或非人声等无效语音,即自动删除无效部分,保留有效语音。这种方式保障识别引擎处理是说话人的声音,并为后面的特征提取部分提供准确的有效语音,提高准确度。
2)噪声消除
在实际应用中,背景噪声对于声纹识别应用是一个现实的挑战,即便说话人处于安静的办公室环境,在电话语音通话过程中也难以避免会有一定的噪声。InterVeri声纹识别系统具备高效的噪音消除能力,以适应用户在千差万别的环境中应用的要求。
(2)语音识别技术
语音识别引擎提供关键字语音识别和连续语音识别,具备优秀的识别率,提供全面的开发支持及丰富的工具,易于使用。
针对语音识别应用中面临的方言口音、背景噪声等问题,基于实际业务系统中所收集的涵盖不同方言和不同类型背景噪声的海量语音数据,通过先进的区分性训练方法进行语音建模,使语音识别在复杂应用环境下均有良好的效果表现。
基于深度学习的语音识别技术,因为采用海量数据进行学习和训练(一般需要数十万小时的语音数据),不同的噪声类型和口音都可以通过人工智能和机器学习的方法进行学习,从而对噪声和用户的不同口音都有比较好的覆盖,这也是语音识别技术可以得到更广泛应用的最先决的条件。
(3)语音内容提取与分析
语音的内容提取与分析技术研究,针对语音内容的自动转写方面,拟采用的技术路线分为三个阶段,分别是:
1)针对语音端点检测与说话人分离
计划收集各种应用场景下的非语音数据,使用深度神经网络技术进行语音与非语音建模,实现高质量的语音端点检测;另外,计划利用BIC(Bayesian Information Criterion)距离在短时上的优势,同时结合PLDA(Probabilistic Linear Discriminant Analysis)在长时声纹相似性评估上的优势,采用两阶段的方法进行分离,充分提高说话人分离的类纯度。
2)面向口语化风格的声学模型
针对口语化发音更加多样化的问题,一方面,计划研究万小时以上的海量语音数据条件下的声学建模,通过收集各种发音风格,提高声学模型对发音变化的覆盖性;另一方面,针对口语化导致的语速快、吞音、回读等问题,计划采用基于模型域、特征域以及特殊音素建模的方法,减少口语化问题的影响;第三方面,计划采用具有时序建模能力的循环神经网络,结合对音素、说话人、环境的预测,进一步提高声学建模能力。
3)面向口语化风格的语言模型
针对口语对话产生的回读、不通顺、语气词等问题,计划使用基于字与基于词结合的循环神经网络建模技术、语义语言模型技术等逐步减少口语化问题的影响。针对语音转写可用充分利用长时信息的特点,计划采用基于N-Gram的篇章级语言模型技术、以及基于循环神经网络的篇章级自适应技术,进一步提高语言模型建模能力。
(4)语音内容理解与摘要
针对语音转写结果基础上的内容理解及摘要,采用的技术路线为:
1)语音转写结果的可读性提升
计划使用基于多信息融合及基于声学属性识别的声学置信度技术,并结合语义信息,进一步提升异常语音的检测能力;计划研究基于CRF(Conditional Random Field)模型的标点技术、基于CRF模型的句子顺滑及基于最大熵模型的关键信息抽取等技术,通过这些技术的组合,进一步改善转写内容的可阅读性。
2)语义段落的自动划分
基于句子级别语义聚类和关联逻辑关系的分析,以及一些特殊的提示型词汇、停顿长度等额外信息,自动将较长的内容转写结果切分为语义相对独立的若干个段落,为关键信息和摘要做准备。
3)语义摘要
借鉴传统的文本自动摘要,并根据语音中说话人、语气强调重复等信息,自动对每一段语音进行关键信息的抽取和自动摘要。
(5)与超声报告系统实现深度结合
为了让系统有更好的体验效果,以及后续对数据的科研运用,语音录入系统跟超声报告系统实现了相互融合:
1)报告界面调用语音录入系统
检查医生在登录超声报告系统后,可以在报告书写界面直接调用语音录入系统,两个系统之间通过标准的HL7协议接口实现患者数据和检查数据的同步。
2)结构化报告通过二维表方式返写回报告系统
在语音录入系统生成的结构化报告,可以通过二维表同步的方式回写到超声报告系统中,从而实现报告系统的结构化存储,为后续科室的科研、统计等工作提供更多便利。
(6)结构化数据全院共享,赋能科研
精细化的医技检查数据是临床科研的重要支撑,结构化的检查报告数据通过严格的授权可以支撑医院专病数据库的建设,加强超声科与临床科研的互动合作。
超声AI语音助手通过语音进行模板内容的录入,实现全程语音交互与结构化报告输入功能,支持常用超声模板,排除闲聊功能,直接将关键信息上到报告相应位置,实现一人同步完成超声检查和报告录入操作,最后只需做少许调整即可输出打印超声报告,极大提高医生的工作效率。
自超声AI语音助手在医院超声科室上线以来,累计完成报告数5723份,其中高频使用前五的模板分别为“肾模板”1951份、“肝胆胰脾”1774份、“甲状腺颈部”1723份、“乳腺腋窝”877份和“颈部血管”467份。
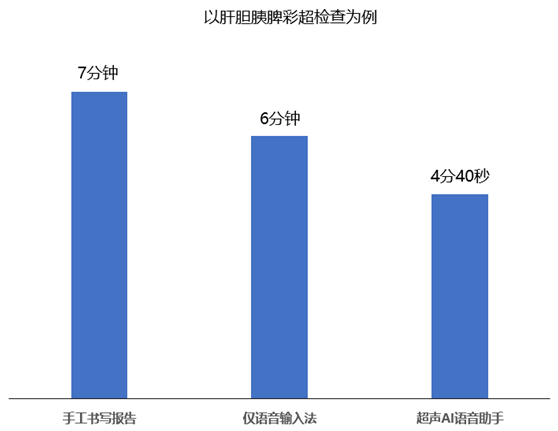
经现场跟诊评估,以标准腹部《肝胆胰脾彩超》检查为例,原检查+手工报告书写流程平均7分钟。在仅使用语音输入法情形下,流程耗时6分钟,效率提升16%。在使用超声语音助理系统场景下,流程耗时4分40秒,效率提升31%,且病人检查过程中即完成报告,无需单独书写。检查过程中需要进行超声造影、病灶等大段额外描述时,语音提升80%完成效率,仅需对格式进行微调即可。检查过程中无需助手辅助书写,医生独立完成数值填值、超声所见描述、超声结论汇总,一定程度减少人力投入。
由语音录入系统生成的结构化报告,无需进行繁琐的后结构化过程即可满足科研数据检索、统计分析的要求,并可针对科研需要进行进一步的内容分类,便于研究者分析患者病情与影像学表现,发现超声表现、历史就诊记录与疾病情况的关联,为研究提供数据支撑。
超声AI语音助手在中山一院超声科的成功应用,标志着医院智能化水平迈上一个新的台阶。将超声科检查报告双人协同的工作模式变革为单人全过程语音操控,实现医生边检查边进行报告录入,不仅提高了医生报告录入效率,而且能够实现所说即说得的报告书写效果。在节省录入员人力成本的同时,通过超声报告质检功能保障报告质量,使医生更专注于对患者的医疗服务,医患沟通更加融洽。下一步,中山一院将探索智能语音技术在其他医技科室及临床科室的场景应用,将智能语音融入到临床诊疗过程中,用人工智能赋能医务人员,真正为医务人员带来便捷的工作帮手,打造符合医院特色的智慧医院建设模式。
申报单位:
中山大学附属第一医院
技术方向:
医学人工智能
业务领域:
临床应用
