

 首 页
首 页福建省立医院:基于机器学习与深度学习的大数据治理平台

CHIMA 2020医院新兴技术创新应用优秀案例征集自启动以来,获得了业内各方的积极响应。CHIMA将陆续刊登参评案例,展示医疗信息技术科技创新应用成果。目前,网络推荐案例投票正在火热进行中,为你心目中的最佳案例拉拉票吧!
为促进和规范全国医院信息化建设,明确医院信息化建设的基本内容和建设要求, 国家卫生健康委员会制定了《全国医院信息化建设标准与规范(试行)》,其中大数据治理对三级甲等医院提出明确要求:以统一的数据标准对多源异构数据进行归一化处理。今年我院构建了全院统一大数据平台,平台汇聚了总量为3T多结构化数据,其中总文本记录数共计700多万份;已实现数据资产统一管理、术语字典标准化、电子病历实现文本后结构化、数据质量监管常态化等数据治理工作。目前,我院利用数据治理之后的数据中心大数据资源,对医疗服务、科研管理、医院治理等方面提供辅助决策和支撑应用。
本案例的核心是构建强大且快速算力的全院统一大数据平台,支持全院各个学科并发而独立的大数据在线应用服务,满足医院各方面大数据应用要求。服务对象包括:医院管理人员、临床医生、护士、检查及检验科室人员等。
整合福建省立医院所有医疗数据资源、构建全院数据资产统一建设与管控平台,保证各个医学中心在统一医院大数据平台上的建设,促进医学研究的转化。当前医院数据集总量为3T多结构化数据,其中总文本记录数共计700多万份。如何制定统一的数据标准,对多源异构数据进行归一化处理;如何提取非结构化文本中的重要信息,通过结构化的形式供其他应用使用等问题凸显,及时得以解决显得尤为迫切。
(1)医学标注
处理文本的 NLP 算法大部分为有监督的机器学习,因此,对于文本的标注工作的“质”和“量”决定了最终 NLP 算法的性能。由于每个人对文本的理解不同,文本标注工作中存在的最大问题是标注的不一致,有文献显示文本标注的一致性仅为75%左右,例如胆汁淤积既可能被标注为“疾病:胆汁淤积”,也可能被标注为“生理物质:胆汁”+“名词性异常:淤积”(图1),一致性上的差异会对模型的训练造成很大影响。
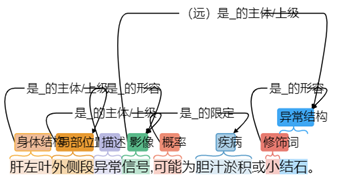
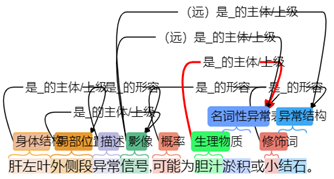
图1 标注不一致示例
为了尽量减少这种不一致性,我们设计了一套标准的分层标注流程来减少医学标注的不一致性,如图2所示。首先我们通过算法对文本进行自动分段,将长文本拆为一个个可独立标注的段落,之后依据标准医学术语对这些段落进行实体标注,然后再将实体之间的关联语义关系标注出来,最后再由不同的医学人员进行交叉审核和修改。
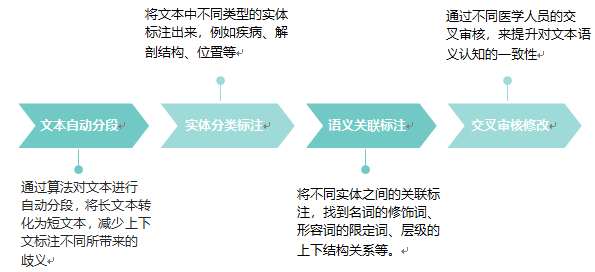
图2 医学标注流程
(2)医学自然语言处理
基于医院的海量病历文书,结合医学文本标注和医学术语网络,使用无监督学习、监督式学习、迁移学习等机器学习方法建立了一整套针对中文医学文本的分层式自然语言处理技术,对医学文本进行信息抽取、结构化转换以及标准化处理,包括分词、词性标记、命名实体识别、句法分析、确信度分类、时序解析、关联抽取、词义解析、扩展消歧、变量匹配等环节。从工程实现上来看,它的基本流程如下所示:
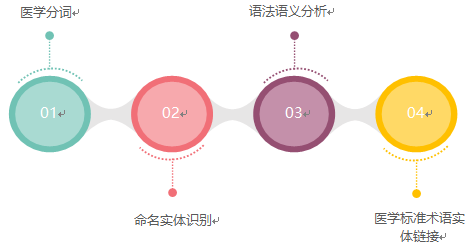
图3 医学自然语言处理基本流程
1) 医学分词模块
进行自然语言处理的第一步就是分词,对于医学自然语言处理来说,分词的好坏直接关系到后续语义解析的准确性,为了将通用词汇与医学词汇更为准确的区分出来,我们参考了ICD-10、ICD9-CM-3、LOINC、ATC等国际和国家标准医学术语集的医学术语,涉及范围包括解剖结构、疾病、症状、检验、药品、手术、化学成分等。
2)命名实体识别模块
医学命名实体识别是医学自然语言处理的核心模块,其目标是识别文本中出现的各类实体,包括疾病、治疗、症状、身体部位等。我们的命名实体识别通过监督式的机器学习,使用深度神经网络模型,其主体结构为ALBERT + BiLSTM +卷积神经网络(CNN)+ CRF嵌合,使用Adaptive Loss联合层参数共享的方式,基于各类临床文书的标注语料进行迁移学习。
3)语法语义分析模块
语法语义分析模块的目的是构建语义网络,我们的语义网络由医学概念实体(术语)、概念关联和语义关联3个部分构成,用以模拟人类(医务人员)认知中对文本理解和知识体系运作的机制,句法分析是构建语义网络的重要环节之一,用以寻找实体跟实体之间的相互关系,常见的关联类型有:限定关系、修饰关系、从属关系等。
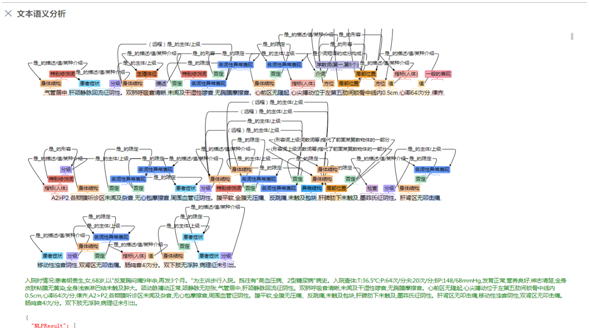
图4 语法语义分析结果
4)医学标准术语实体链接模块
我们在解析语法语义之外,需要对变量进行结构化提取,而这个环节就是医学标准术语实体链接模块来实现的。此模块依据与我们对于结构化变量的定义,综合监督式学习和特定规则进行计算,输出语义网络中的标准概念实体。监督式部分包括义元识别和基于图嵌入的加权语义相似度计算,义元识别类似于命名实体识别模型,使用CRF和基于同义义元表的最长串匹配算法进行序列标注。结构化变量提取效果(如图5)所示。
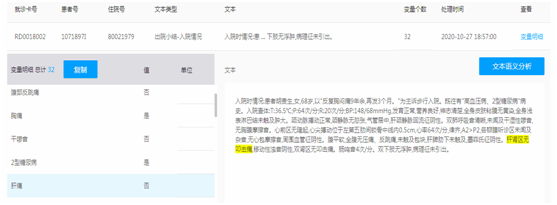
图5 结构化变量提取示例
(3)医学术语标准化治理模型
在充分参照国际和国家医学术语标准体系的同时,我们利用算法建立了一套可以对不同医学术语进行自动标准化的系统,实现对医学术语的自动归一化。该系统主要包括医学表达知识库、医学术语召回层和医学术语排序层,其中医学表达知识库中由于积累了大量的相似医学表达,例如哮喘、喘息、哮喘性、喘息性等,我们在知识入库的过程中加入了自动知识冲突检测模型,针对相似内容医学表达可能的冲突情况进行自动检测,并自动选择最佳的表达方式入库。
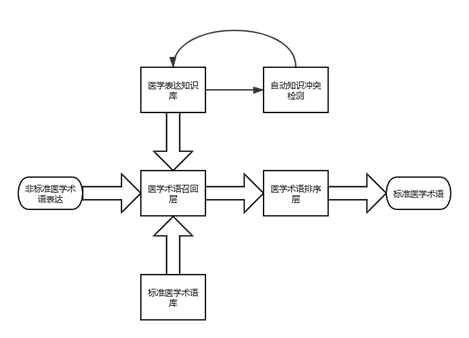
图6 医学术语自动标准化治理模型
(4)数据质量核查
数据质量问题一直是大数据应用的老大难问题,没有足够好的数据质量,数据应用也无从谈起。我们通过平台化数据质量监控和规则库的配合,让大数据平台的所有用户能够对自己提供的数据进行数据质量管理,在数据质量模块上方便自如的配置需要的监控规则、查看结果并进行后续处理,系统会根据质量问题的分级,自动对数据质量问题进行不同级别的预警,以便进行不同级别的人工响应。
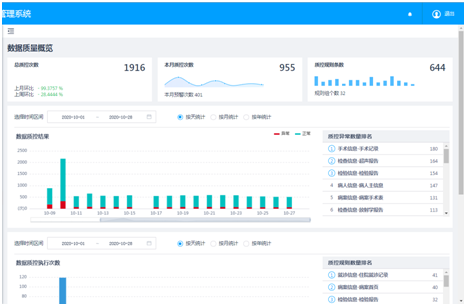
图7 每日数据质量监控概览
(1)实现数据资产统一管理

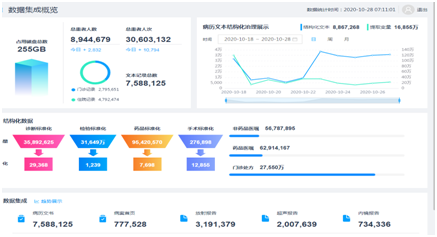
图8 数据资产统一管理
(2)实现术语字典标准化
字典标准化经常会对数据应用造成巨大的困扰,尤其是医学字典的标准化。像诊断、检验、药品、手术这些字典,由于字典的数量巨大,且临床表达多样,在不同应用系统和场景中经常同样一个概念会被表述为几十个甚至上百种不同的表达,通过人工对照的方式难以实现和维系。对此,我们将上述医学术语自动标准化治理模型封装为医学术语自动映射引擎,再通过人工审核和修正。

图9 术语字典标准化
(3)电子病历实现文本后结构化
通过自然语言技术对常用文本类型,如首次病程、日常病程、胸片、心电图、入院记录等,做后结构化处理,提取文本中的变量。像入院记录-主诉,可以提取的变量样例有咳嗽、发热等,他们的值是布尔类型,代表着是否的意思。是否咳嗽,是否发热等。有了这些变量,可以方便对文本数据进行检索与利用。
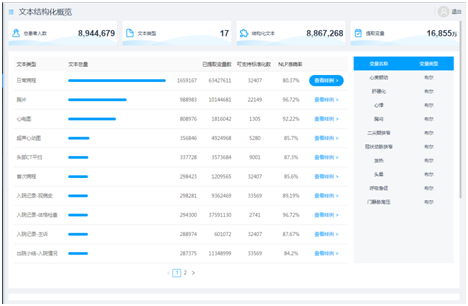
图10 电子病历实现文本后结构化
(4)数据质量监管常态化
在数据治理后,要进行数据质控。我们建成了数据质量管理系统。按照不同的业务数据类型,制定不同的质控规则。从数据的完整性、有效性、一致性等多个维度对不同的字段设置校验规则。规则设置完成之后,会自动实时运行。运行结束后,会自动生成一个完整的质量报告。这是每日执行的质控报告,点击查看详情,可以看到数据质控覆盖范围和质控执行的情况。
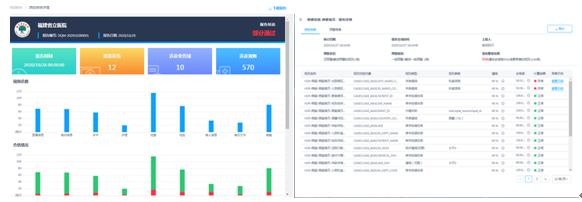
图11 数据质量监管
依托福建省立医院大数据实验室为平台,将结合临床指南,对数据资源整合、数据利用、数据质量、数据权益和安全等方面的职责和管理体系进行规范研究,建立完善的理论体系和技术框架来指导、监督和评估医疗大数据治理工作,满足医疗行业中临床诊疗、机构运营、学科建设、卫生管理等高速发展的要求。
申报单位:
福建省立医院
参选方向:
医院数据治理建设


点击此处即可进行投票
