
 首 页
首 页安志萍:医疗诊断中不平衡数据集的处理策略及建模分析研究
研究背景
不平衡数据集是指数据集中各类别样本数量分布显著不均,通常表现为某一类或某几类样本(少数类)的数量远远少于其他类别样本(多数类)。在人工智能应用中,对不平衡数据集进行研究至关重要。因为大多数分类算法均假设数据分布相对均衡,分布不平衡会导致传统的机器学习模型在训练过程中过度偏向多数类,从而降低对少数类的识别能力,模型倾向于将所有样本预测为多数类,从而在评估指标上“掩盖”了其失效的本质。这使得模型在实际部署中,尤其是在那些少数类恰恰代表关键事件(如故障、欺诈、疾病)的场景下,几乎失去应用价值。
这一问题在医疗诊断领域中尤为突出且影响重大。医疗数据往往呈现出极端不平衡性,例如在罕见病筛查、癌症早期诊断或重症风险预测中,阳性病例或高危样本在全体人群中占比极低,但在临床决策中却具有至关重要的地位。若直接应用传统分类模型,极易导致对疾病样本的漏诊,即模型敏感性极低。这种“高准确率”但“低识别率”的诊断系统在临床上不仅是无效的,甚至可能因延误治疗而造成严重后果。因此,针对医疗领域不平衡数据集的研究,是提升诊断模型敏感性、特异性及临床可信度的关键,具有重要的理论价值与现实意义。
本研究旨在探索适用于医疗诊断场景的不平衡数据处理策略,并评估其对模型性能的影响,以期为提升医疗诊断系统的实际应用价值与临床意义提供参考。
不平衡数据集的处理方法
1.数据采样优化
采样技术作为解决数据不平衡问题的重要手段,主要包括过采样和欠采样两种方式。
(1)过采样(Oversampling) 。是指通过复制或合成少数类样本,以增加其在数据集中的比例,从而缓解类别分布不均的问题。其中,合成少数类过采样技术(SMOTE,Synthetic Minority Oversampling Technique)是一种广泛应用的方法。该方法通过在少数类样本之间均匀生成合成样本,以增加数据多样性,主要关注于填补少数类分布中的空白区域,能有效缓解过拟合,且计算成本较低。然而,SMOTE在实际应用中也存在一定局限性,例如可能引发过泛化或收敛不稳定等问题。
而自适应合成过采样方法(ADASYN)的核心思想并非简单复制少数类样本,也不像SMOTE均匀合成新样本,而是基于少数类样本的学习难度有侧重地生成合成样本。其通过自适应机制,将生成样本的重点放在分类边界附近及难以学习的少数类样本上,从而更有效地提升模型对决策边界的学习能力。
(2)欠采样(Undersampling) 。与过采样相对应,欠采样则是通过减少多数类样本的数量来平衡数据集。该方法虽然能简化模型训练过程,但也容易造成信息丢失,从而影响分类器的准确性。
而随机欠采样(Random Undersampling)是从多数类中随机移除部分样本,使数据集中两类样本的数量达到平衡(通常为1:1或其他比例)。该方法能降低计算成本,由于数据集规模减小,模型训练和预测速度会明显提升。然而,随机丢弃的多数类样本可能包含重要信息,导致模型无法充分学习多数类的分布特征,从而引起欠拟合。
2.分类算法优化
分类算法优化方法聚焦于改进或设计新的分类算法,以增强其在不平衡数据上的适应性。例如,传统的Boosting算法在处理不平衡数据时表现不佳,因其在更新样本权重时对正类和负类采用相同的调整比例。有研究者提出一种改进的Boosting算法,在权重更新过程中对正类和负类赋予不同的调整量,从而有效提升对正类的识别精度。这类方法不改变样本分布,而是通过调整算法参数使其对少数类更加敏感,然而在少数类样本无法准确反映真实分布的情况下,容易导致过拟合学习现象。
3.集成学习优化
集成学习则结合上述两种方法的优势,有效提升模型的泛化能力和稳定性,尤其在少数类样本识别困难的问题上表现出更强的适应性。例如,通过在训练过程中结合随机欠采样与Boosting机制,能够在一定程度上缓解多数类样本对模型训练的主导影响,从而提升对少数类的识别能力。基于SMOTE的集成学习方法,通过在数据层面引入合成样本,进一步丰富了少数类的分布特征,有助于改善模型的分类效果。
综上所述,针对医疗诊断中的不平衡数据问题,应根据具体任务需求和数据特性,选择适宜的处理方法,以实现更优的分类性能。
分类预测模型评估指标
针对不平衡数据集处理方法及其分类效果的研究,评估指标的选取至关重要。常用的分类评估指标包括准确率(Accuracy)、召回率(Recall)、F1分数(F1_Score)和精确率(Precision)。
在不平衡数据场景下,医疗数据中的正类(如患者)往往远少于负类(如健康人群),传统分类准确率指标容易受多数类主导,难以真实反映模型对少数类的识别能力。因此,分类器不仅需具备较高的总体准确率,还应在少数类的召回率与精确率之间取得良好平衡,以确保诊断的敏感性与特异性。
因此本研究基于混淆矩阵提取关键参数,如真正例(TP)、真负例(TN)、假正类(FP)和假负类(FN),通过综合运用特异度(Specificity)、假阴性率(FNR)及假阳性率(FPR)等指标,构建多维度评价体系,全面评估模型在医疗不平衡数据集中的实际表现,为后续模型优化与临床适用性提供可靠依据。
1.特异度(Specificity) 又称为真阴性率(True Negative Rate, TNR),是评估模型正确识别负类样本的能力,即所有实际为负类的样本中,被正确预测为负类的比例。通俗理解“模型不误报的能力”,即实际没病的,有多少被正确诊断为没病。
2.假阴性率(FNR,False Negative Rate)用于衡量实际为正类的样本中,被错误预测为负类的比例。该指标可通俗理解为“漏诊率”,即实际患病但未被模型识别出的病例所占的比例。
3.假阳性率(FPR,False Positive Rate)用于衡量实际为负类的样本中,被错误预测为正类的比例。该指标可通俗理解为“误诊率”,即实际健康但被错误判定为患病的样本所占的比例。
基于肝癌数据集的数据采样处理及构建分类预测模型的示例研究
选择合适的策略处理不平衡数据,是构建有效医疗诊断模型的关键步骤。本研究采用肝癌数据集,通过不同采样方法进行数据预处理,并对每个处理后的数据集均使用随机森林分类算法构建分类预测模型,进而系统对比各项模型性能。
技术工具采用:Python 3.7 + PyCharm 2022.2(Community Edition)。
1.数据集介绍
本研究采用的肝癌数据集来自Kaggle,是一个在医学上具有现实性的肝癌分类数据集,具有影响肝癌风险的真实世界患者属性,结合了人口统计学、生活方式、临床和基于生物标志物的特征。本研究将数据集构造为不平衡结构,选取666条肝癌样本与3911条健康样本进行分析与建模。数据无空值记录、无重复记录,各字段取值规范统一,质量评估结果表明该数据集符合建模要求,能够为后续分析提供可靠基础。
该数据集包括以下14个特征字段:
(1)Age 患者年龄(岁),范围30-85 ;
(2)Gender 患者性别 (男, 女);
(3)BMI 身体质量指数,数据范围约16-45;
(4)Alcohol_Consumption 饮酒情况:从不、偶尔、经常;
(5)Smoking_Status 吸烟行为:从不、曾经、当前;
(6)Hepatitis_B 乙型肝炎感染情况 (0=否, 1=是);
(7)Hepatitis_C 丙型肝炎感染情况 (0=否, 1=是);
(8)Liver_Function_Score 模拟的肝功能评分,范围0-100;
(9)Alpha_Fetoprotein_Level 甲胎蛋白水平,单位 ng/mL;
(10)Cirrhosis_History 肝硬化病史 (0=否, 1=是);
(11)Family_History_Cancer 癌症家族史 (0=否, 1=是);
(12)Physical_Activity_Level 体力活动水平:低、中、高;
(13)Diabetes 是否患有糖尿病 (0=否, 1=是);
(14)Liver_Cancer 目标变量 最终诊断结果 (0=无癌, 1=患有肝癌)。
2.数据预处理
为便于机器学习算法处理,对数据集中包含的字符型特征,如Alcohol_Consumption、Gender、Smoking_Status等,进行分类编码,并对所有数据进行标准化处理。
在数据预处理阶段,针对数据集中存在的样本分布不平衡问题,引入多种采样方法处理进行直观对比,包括过采样方法SMOTE、ADASYN,及随机欠采样Random Undersampling。为克服过采样与欠采样的局限性,又引入两种混合集成方法。该类方法主要结合“过采样(SMOTE)”与“数据清洗”步骤,旨在缓解单纯使用SMOTE可能引入的噪声问题,期望提供结构更合理、分布更贴近原始数据的处理方式。
(1)SMOTE + Edited Nearest Neighbors (ENN)。该方法首先使用SMOTE对少数类进行过采样,以实现类别平衡。随后,应用编辑最近邻(ENN)方法对数据进行清理,即如果一个样本的K个最近邻中大多数属于另一个类别,则该样本会被删除。该方法的优势在于能够有效清理类别边界模糊区域中的噪声点和异常点,从而缓解了SMOTE可能引入“可疑”样本的问题。
(2)SMOTE + Tomek Links。该方法首先使用SMOTE对少数类进行过采样,以达到类别平衡。接着,识别并处理Tomek Links样本对。Tomek Link指的是属于不同类别且互为最近邻的一对样本,这类样本通常位于决策边界或类别重叠区域。常见的处理方式是移除Tomek Links中的多数类样本(有时也可能移除双方样本),以此扩大两类之间的间隔。该方法的优点在于能够有效识别并清理边界附近的“模糊点”,使类别之间的区分更加清晰。
3.数据分布对比分析
本研究采用五种方法对不平衡数据集进行处理,为便于后续论述,将原始数据集与经五种方法处理后的数据集分别表示为:original数据集、smote数据集、adasyn数据集、undersample数据集、smote_enn数据集和smote_tomek数据集。

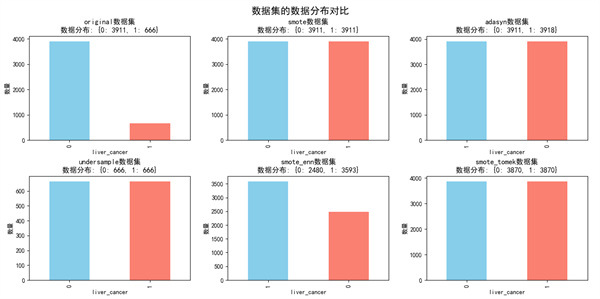
图1 不同数据集的数据分布对比图
图1显示,在原始数据集中,0类样本有3911例,1类样本仅有666例,存在明显的类别不均衡。经过不同采样方法处理后,各类数据集分布呈现显著差异:
(1)smote与adasyn数据集中的两类样本数量均增至约3911例,数据规模最大;
(2)undersample数据集的两类样本均减少至666例,数据规模最小;
(3)smote_enn数据集中0类样本降至2480例,1类样本增至3593例;
(4)smote_tomek数据集的两类样本均保持在3870例。
综上可知,过采样方法通过增加少数类样本数量以增强其在训练中的影响;欠采样方法则通过削减多数类样本以缓解其主导作用;而集成采样方法通过生成合成样本而非简单复制,进一步优化了数据分布。
4.构建肝癌患者分类预测模型及模型性能对比
本研究采用随机森林算法构建肝癌患者分类预测模型,主要参数设置为:n_estimators=100。数据集按0.2的比例划分为训练集与测试集。

图2 不同数据集构建分类模型的混淆矩阵对比图
图2为不同数据集分类预测模型的混淆矩阵对比。结果显示:
(1)smote_enn数据集的阳性预测准确率最高,达到97.64%,阴性预测准确率为89.92%;
(2)original数据集的阳性预测准确率为51.88%,阴性预测准确率为99.74%;
(3)smote数据集分别为91.94%和89.53%;
(4)adasyn数据集分别为92.98%和87.85%;
(5)undersample数据集分别为94.74%和88.81%;
(6)smote_tomek数据集分别为91.73%和88.89%。
通过对比可知,在对不平衡数据集进行重采样处理后,模型对阳性样本的识别能力(召回率)得到显著提升。其中,SMOTE_ENN集成方法在保持较高阴性预测准确率的同时,取得了最优的阳性识别性能,体现了集成采样方法在平衡分类效果上的综合优势。这表明通过恰当的数据重采样技术,能够有效改善模型对少数类的识别能力,从而提升分类器在不均衡数据场景下的整体性能。

图3 不同数据集构建模型的综合指标热力图
图3为不同数据集综合性能指标的热力图,从各指标分析可知:
(1)准确率(Accuracy):排序最高的依次是smote_enn数据集、original数据集,最低的是smote_tomek数据集;
(2)精确率(Precision):排序最高的依次是original数据集、smote_enn数据集,最低的是adasyn数据集;
(3)召回率(Recall):排序最高的依次是smote_enn数据集、undersample数据集,最低的是original数据集;
(4)F1分数(F1_Score):排序最高的依次是smote_enn数据集、undersample数据集,最低的是original数据集;
(5)特异度(Specificity):排序最高的依次是original数据集、smote_enn数据集,最低的是adasyn数据集;
(6)假阴性率(FNR):该指标越低表示性能越好,图中颜色越深代表数值越低,排序最前的依次是smote_enn数据集、undersample数据集,最末的是original数据集;
(7)假阳性率(FPR):该指标越低表示性能越好,图中颜色越深代表数值越低,排序最前的依次是original数据集、smote_enn数据集,最末的是adasyn数据集。
综合分析表明,原始数据集虽然精确率和特异度表现突出,但在召回率、F1分数及假阴性率等少数类识别相关指标上表现欠佳,反映了类别不平衡对模型识别能力的负面影响。过采样方法在提升少数类召回率的同时,可能因样本重复引入过拟合风险,导致泛化性能波动;随机欠采样虽在部分指标上表现较好,但可能因信息丢失而引起模型欠拟合。相比之下,集成采样方法在多数关键指标上均表现优异,尤其是在召回率、F1分数与假阴性率方面显著优于其他方法,说明其在增强少数类识别能力的同时,能较好地平衡各类别之间的性能,避免单一采样策略的局限性,展现出更稳健的分类综合性能。
5.分类预测模型错误对比分析

图4 不同数据集构建分类模型的错误分析对比图
对不同数据集分类预测模型的错误情况进行对比,如图4所示:
(1)总错误数分析:在样本量较为接近的smote、adasyn、smote_enn和smote_tomek数据集中,smote_enn数据集的总错误数显著最低。而undersample数据集因整体样本量最少,总错误数也相应最低。
(2)错误类型数量对比:在样本量较为接近的数据集中,adasyn和smote_tomek数据集的假阳性(FP)数量明显高于smote_enn数据集,而original数据集的FP数量最低。在假阴性(FN)数量方面,smote_enn数据集仅高于undersample数据集。
(3)错误率对比:在假阳性率(FPR)方面,original数据集表现最优,其余数据集较为接近,其中smote_enn数据集相对最低。在假阴性率(FNR)方面,smote_enn数据集显著低于其他数据集。
(4)FP错误占比:即FP数量占总错误数的比例,图中显示smote_enn数据集的该比例为最高。
综合以上分析可知,尽管smote_enn数据集在假阳性绝对数量上并非最低,但其在总错误数、假阴性率等关键错误指标上表现突出,尤其在减少对少数类的误判(即假阴性)方面具有明显优势。这进一步说明,SMOTE_ENN这类集成采样方法能够更有效地权衡两类错误,在整体控制错误数量的同时,显著提升对少数类样本的识别能力,从而在实际应用中可能提供更可靠的分类性能。
6.数据集平衡效果对比分析

图5 不同数据集构建模型的平衡效果分析图
对不同数据集平衡处理后的效果进行对比,如图5所示:经采样方法处理后,各数据集的不平衡比例显著降低,整体分布趋于平衡。随着数据集中少数类比例的增加,模型对少数类的识别能力(召回率)相应提升,其中smote_enn数据集的召回率达到最高。同时,随着数据集趋于平衡,模型的综合评价指标(F1分数)也显著提高,smote_enn数据集同样在此项指标上表现最佳。
研究结果
综上可知,本研究中针对不平衡数据集采用不同的采样策略,能有效改善分类模型的预测性能。其中,集成采样方法SMOTE_ENN在多个关键评估维度上表现突出:在混淆矩阵分析中取得最高的阳性预测准确率;在综合性能热力图中于准确率、召回率、F1分数及假阴性率等指标上均名列前茅;在错误分析中其总错误数最低且假阴性率控制最好。这些结果一致表明,SMOTE_ENN方法在有效平衡类别分布的同时,能够显著提升模型对少数类的识别能力,并较好地兼顾整体分类性能与泛化能力,避免了过采样可能导致的过拟合与欠采样可能造成的信息丢失问题。
因此,在医疗诊断这类对少数类识别具有较高要求的应用场景中,这种综合优化的策略不仅增强了模型对不平衡数据的适应能力,而且减少了因数据分布不均导致的预测偏差,为临床辅助诊断提供了可靠的技术支持。这一研究为未来在医疗领域应用机器学习技术提供了有价值的参考和实践路径。
作者简介
安志萍,高级工程师,在职博士学历,专业技术上校退役。CHIMA委员,中国研究型医院学会医疗信息化分会理事,中国医疗保健国际交流促进会医学工程与信息学分会委员,中国医学装备协会医院物联网分会常务委员。长期从事医院信息化建设工作。作者观点纯属与同行做技术交流,欢迎批评指正。
